
What if you overheard a health plan CIO give this command: “Alexa, over the last three months, which New York providers received the most payment for treatment of out-of-state patients with chronic conditions?”
Ridiculous, right? After all, Alexa is merely a voice-activated assistant, not a miracle worker.
But maybe it’s not so ridiculous.
Maybe the foundational barriers to a frictionless experience for healthcare executives and consumers alike — data quality, data standardization and data integration across healthcare data sets and systems— are about to be abolished by the convergence of some very powerful and profound market, government and technological forces.
Healthcare has long lagged other industries in transforming business models through technology (for all kinds of reasons), yet we know from our own research that healthcare organizations that embrace digital transformation are three times more likely to achieve improvements in their operational metrics.
We also know from our research that those making the most progress approach their journey to digital transformation as a series of many smaller steps with commonly defined, accepted and communicated goals. Meanwhile, a full 78 percent of those we surveyed said they feel like their digital initiatives are not yielding the expected results.
Whether your digital initiatives are floundering or you want to make sure they don’t, you can be sure that your data very much dictates your success or failure:
- Do you have the right data?
- Do you have data integrity? Does your data pass the quality test?
- Is you data integrated across your systems and applications?
- Are you using the right tools and technologies to drive the intended outcome?
This is where emids analytics and business intelligence experience and models excel.
During our focused work in healthcare over more than two decades, we have developed common data models (using HL7 and FHIR standards) that are proven to save time, improve the quality of the solution and reduce costs. What’s more, our proprietary models are repeatable across healthcare organizations and industry segments.
Before we get into the specifics of our models, let’s look at the forces driving even higher demand for data models and business intelligence that work.
STRONG TECHNOLOGICAL AND MARKET FORCE WINDS
When you consider the growth and proliferation projected for Alexa and her voice-activated peers (Google Assistant, Siri, etc.) over the course of the next two years alone — researchers predict there will be almost as many voice-activated assistants on the planet as people by 2021 — Alexa’s ability to help a health system CIO realize his or her command may not be as far fetched as it sounds.
In fact, as virtual assistants gain traction at home and in business, these same researchers predict that AI assistants will build on their potential as health companions and organizers, gaining relevance as key enablers of health care… wherever consumers choose to access it.
This is the kind of frictionless world that policymakers, entrepreneurs and engineers alike envision, yet all agree that considerable friction remains. As Taniya Mishra recently explained in The Atlantic, one of the biggest challenges with voice is, “building big-enough and sufficiently diverse databases of language from which computers can learn.”
“Classification is a slow, painstaking process,” she explained. “Three to five workers have to agree on each label. Each hour of tagged speech requires as many as 20 hours of labeler time.”
The progress that’s been made to date is mind-boggling, and while much work remains, the achievements have blown the door wide open to continued advancement at exponential speed. Technology is a fast learner, but it still needs the human teacher.
The reality is, the very thing that has gotten Alexa as far along as she is, is the very thing that will continue to allow her (and all of our other technological advancements) to advance: human beings behind the scenes figuring out how to make the data do what we want it to do, and then putting teams of people to work to build and train the deep learning systems that power her.
When we talk about Big Data, or machine learning (ML) or artificial intelligence (AI) in healthcare, what we’re talking about are just the means to an end. What we’re really solving for are business problems: how can we improve health, improve patient engagement and reduce the cost of care?
This is where Business Intelligence & Analytics come in: to help organize the data, to make sense of the data, and to analyze the data to provide insights for business decisions.
After all, in their simplest terms:
- Big Data is nothing more than the analysis of extremely large data sets to reveal patterns, trends, and associations;
- ML is the classification of things into different buckets based on patterns so that the machine can use those classifications to learn and can put things into the right buckets or take action or create new ones; and
- AI is about teaching the system what to do, including how to process and analyze large amounts of human language (aka natural language processing, or NLP). AI makes it possible for machines to learn from experience , adjust to new inputs and perform human-like tasks.
The biggest payer in the healthcare system, the federal government, understands this, of course, and understands the barriers, which leads me to forces perhaps more powerful than technology itself: Washington’s actions of late.
To achieve Digital Transformation, organizations must have underlying data assets that are integrated and interpreted consistently within their organizational boundaries. Layering new-age technology tools on top of low- or poor-quality data will certainly lead to failure on the Transformation journey.
STRONG GOVERNMENT FORCE WINDS
To date, regulations, varying data formats, and the siloing of data in and among health payers and providers have made it difficult to pull (and pool) data from multiple sources (that integration factor I mentioned earlier). But a recently signed executive order, the “American A.I. Initiative,” is meant to spur the development of AI across government, academia and industry in the United States (and compete with the likes of China, for one). According to this New York Times article, “the administration will encourage federal agencies and universities to share data that can drive the development of automated systems. … Pooling health care data is a particularly difficult endeavor.”
Immediately following that executive order, leaders from the CMS and the Office of the National Coordinator for Health Information Technology fanned out across HIMSS19 in Orlando to talk up two significant proposed regulations requiring healthcare providers and insurers to implement open data-sharing technology that they say will “finally put patients in the driver’s seat.” The proposed rules are meant to push the industry to make use of application programming interfaces to speed up how patients can access information (and their own healthcare data) on their mobile devices.
That’s all well and good, you say, but maybe you’re like so many of our clients who struggle with what it all means and with knowing where to start on this digital transformation journey.
It’s complex, no doubt, but it’s also quite simple. It starts with a common understanding of data integration, data standardization and actionable steps to take to achieve both. Data integration is integral. To achieve that you need to standardize your data. And to do that better and faster, you need to be able to leverage ML, AI and NLP to automate as many tasks as possible.
USE CASE AND A SOLID FRAMEWORK FOR HEALTHCARE DATA STANDARDIZATION
Let’s use the example of a bot. We hear a lot about bots, but a bot alone isn’t going to solve your problem. What you really need to think about and consider and address is the integration required to make that bot successful. If it’s a bot associated with, say, a payer wanting to make member engagement effective, that might require data from almost every part of the healthcare ecosystem… from payers and providers to population health, life sciences, CROs to regulators, public health entities, pharmacies, applications and medical devices.
Making that possible starts with a solid understanding of your data needs. You need to:
- Improve the confidence of your data assets by improving the quality of your data.
- Have the ability to use data across the organization for business improvement as well as for research and development.
- Ensure easy data distribution with minimal disruption for downstream systems.
- Have the ability to scale, add new data segments and manage data quality.
- Improve the adoption of analytics and data sciences by giving data that is comparable, usable for statistical and analytical purposes, and is as close to 100% correct as possible.
Understanding how your data is classified is also of the utmost importance when it comes to getting that data set ready for any algorithm. There are five buckets of healthcare data, and there is only about 46% of it (the “administrative” data) that isn’t strictly bound by industry dataset standards:
- Patient data (7%)
- Clinical data (14%)
- Drug administration data (15%)
- Lab observation data (18%)
- Administrative data (46%)
When classifying your data, keep these things in mind:
- Implement or classify data based on standard data models.
- Use industry codes and reference data to enrich data sets.
- Involve business stakeholders for classification exercise.
- Define standards for each category.
- Follow or implement data governance policies for data quality rule definition, data correction, and review approval process.
- Subscribe industry reference data for identified categories.
- Remember that the volume of data for correction is a major challenge in standardization.
My best advice: don’t start from scratch, and don’t try to figure it out on your own when there are partners like emids who have spent the past 20-plus years in the healthcare data trenches. Our unique framework for healthcare data standardization has helped hundreds of healthcare organizations with their data integration problems, and we’re continually improving it.
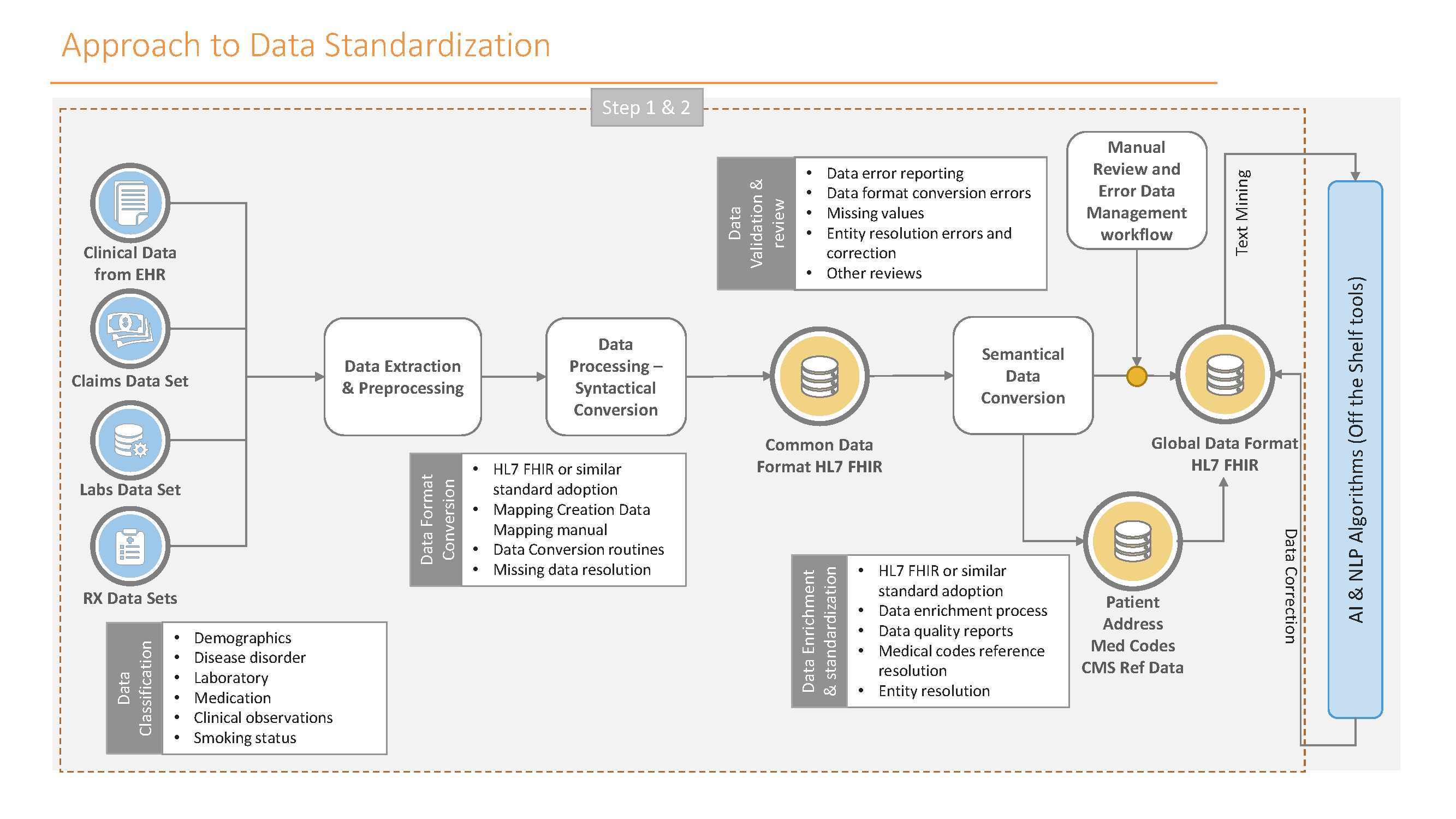 In my upcoming blogs, I’ll dive deeper into the unique challenges and opportunities in each of these important areas. Until then, feel free to connect with me on LinkedIn or at Nilesh.Patil@emids.com
In my upcoming blogs, I’ll dive deeper into the unique challenges and opportunities in each of these important areas. Until then, feel free to connect with me on LinkedIn or at Nilesh.Patil@emids.com
Nilesh Patil oversees Data Management and BI practice at emids. He is a focused business and technology expert with extensive experience developing enterprise information technology strategies and road maps, information architecture, standardized business metrics and analytical infrastructure. This comprehensive technology is designed to deliver vital information to industry organizations in innovative and insightful ways. Nilesh also serves as a valued advisor to multiple healthcare CIOs, CTOs and CAOs on their organizational initiatives, and plays a crucial role in assisting with developing actual blueprints and executing implementation. His skillset as a respected innovator and technology guru lends itself well in leading emids’ platform to help healthcare organizations realize their diverse analytics visions.
Resources and relevant links:
https://www.emids.com/digital-transformation/
https://www.nytimes.com/2019/02/11/health/artificial-intelligence-medical-diagnosis.html


